-
干妹妹 中国联通业界初度提议大模子才气鸿沟量化基准
发布日期:2024-12-29 16:33 点击次数:198
IT之家 12 月 27 日音讯干妹妹,据中国联通官方当天音讯,该公司鉴戒动物智能演化规则,麇集大模子本体落地哄骗践诺,在业界初度提议大模子才气鸿沟量化基准,定量分析主流谈话大模子才气鸿沟,安祥描述模子参数目、模子才气与哄骗场景之间的联系,为谈话大模子的哄骗选型提供表面和请示携带,将有助于裁减谈话大模子哄骗门槛。
谈判谈判后果以 <What is the Best Model? Application-Driven Evaluation for Large Language Models> 为题发表在当然谈话科罚泰斗会议 NLPCC 2024 上,相应的评估基准已向业界开源。
鉴戒动物智能演化规则
一般来说,动物的脑神经元越多,脑容量越大,技术水平就越高。另外,不同技术水平的动物擅长的任务种类和难度也各不雷同,即使小如乌鸦的大脑,也不错完成“乌鸦喝水”这么的任务。
动物智能演化规则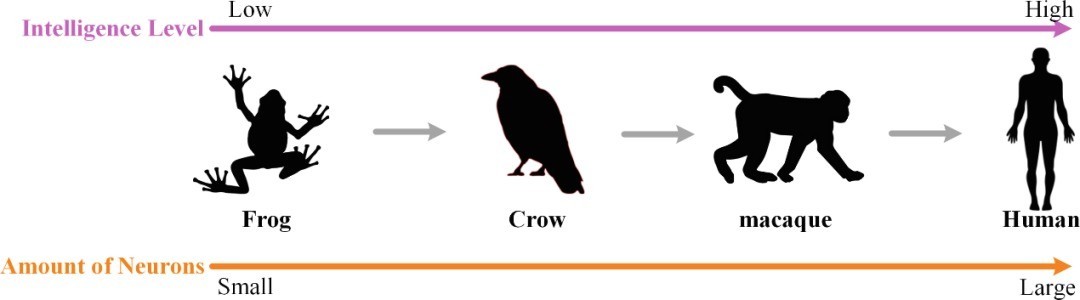
相似地,在谈话大模子中,彭胀法例指出模子参数目越大,模子才气越强,痴迷系列相应的算法破钞和哄骗本钱也越高。然而这么的定性分析是不够的,大模子才气鸿沟定量描述的清寒,导致在本体哄骗中频繁出现“高射炮打蚊子”的情况。因此对大模子才气鸿沟的定量描述是必要且进军的。
构建大模子才气评估基准中国联通谈判团队从本体哄骗场景维度启航,对谈话大模子主要才气进行归纳、梳理和回想,配置了哄骗动手的大谈话模子才气评估基准。该评估基准包括文本生成、融会、要津信息抽取、逻辑推理、任务筹议等 5 大类才气,又细分为 27 类子才气。
谈话大模子主要才气
针对 27 类子才气,中国联通谈判团队构建了相应的评测任务和由易、中、难三个难度品级的 678 个问答对组成的评估数据集。为幸免数据清楚问题,所稀有据均由内行团队东谈主工编写。
哄骗动手的谈话大模子才气评估数据集量化主流大模子才气鸿沟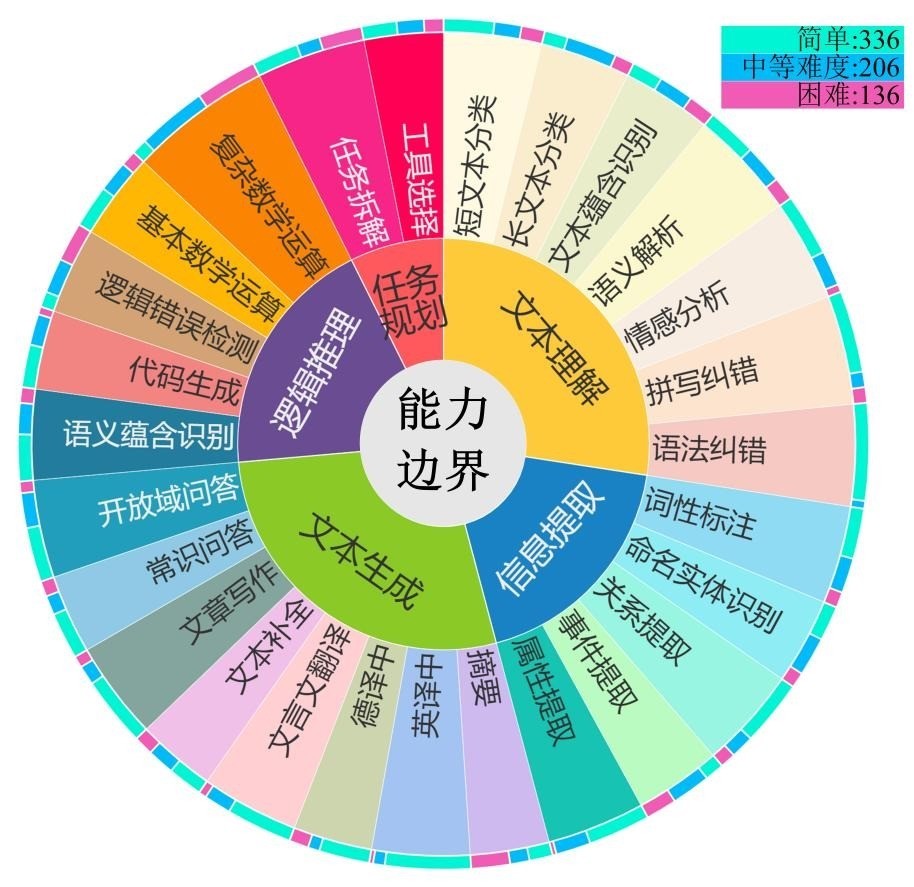
团队遐想了内行评估和基于大模子的自动化评估技术,对吞并眷属 8 个不同鸿沟的模子(0.5B、1.8B、4B、7B、14B、32B、72B、110B)进行测试和评估,幸免模子架构、磨真金不怕火数据等非模子参数目身分对评估摒弃产生烦嚣,取得了不同参数目模子在多样任务上的可靠的评估摒弃。从下图的评测摒弃不错看出,不同参数目模子才气不同,模子参数目越大,模子才气越强,关于复杂任务需要使用大参数目模子。
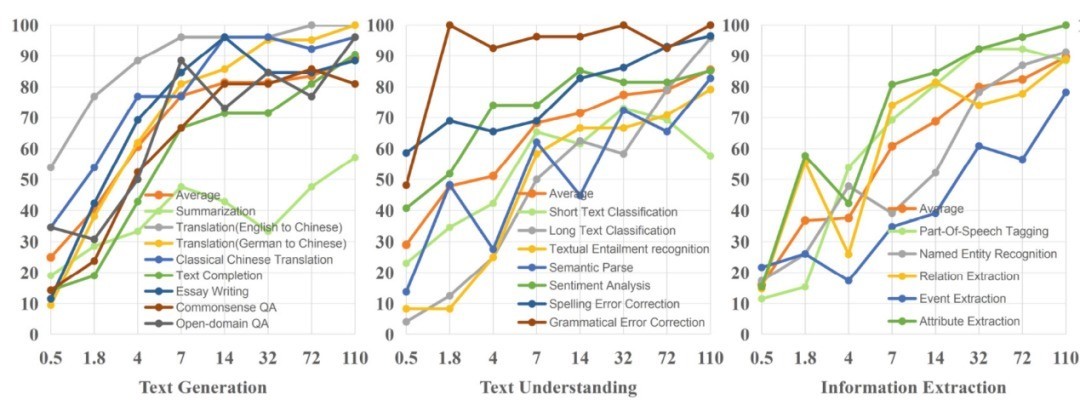
不同参数目模子在各样任务中的准确率依据才气条款细目模子参数目
字据谈话大模子才气鸿沟测评摒弃,团队提议了一种简单可行的模子选型技术,携带模子落地哄骗时的参数选型。总的来说,针对不同任务,任务难度越高条款参数越大;针对吞并任务,参数越大模子性能越好。
具体地,可依据某项任务对模子性能的底线条款来选拔相应参数的鸿沟,以图中任务为例:
在用户需求准确率为 80% 的前提下,关于拼写造作矫正任务,14B 以上模子可获 90 分以上;
关于逻辑造作检测任务,110B 以上模子可达 90 分以上;
如若同期哄骗多个任务,先为每个任务选拔顺应的模子,再选拔其中参数目最大的模子即可。
选型流程中不需要用户对大模子有深化了解,这将裁减用户选拔使用大模子的门槛,促进大模子普惠化。
模子参数目选拔技术示例探索遐想模子选型使用“明白书”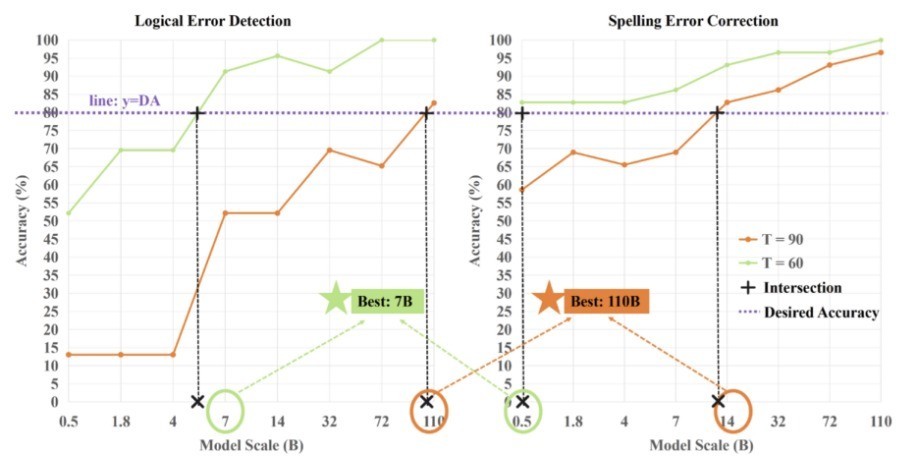
在元景大模子哄骗落地中,中国联通基于上述评估基准,打造评估用具,量化 1B、7B、13B、34B 和 70B 等元景基础大模子的才气鸿沟,并分辩将其用于非法短信分类、投诉工单分类、客服助手、渔业学问问答、元景 App 问答等场景,索求“模子参数目-模子才气-哄骗场景”关联联系(如下图),当作大模子使用“明白书”,集成到元景 MaaS 平台,为设备者提供选模子相易。
色综合模子参数目-才气-场景的对应联系图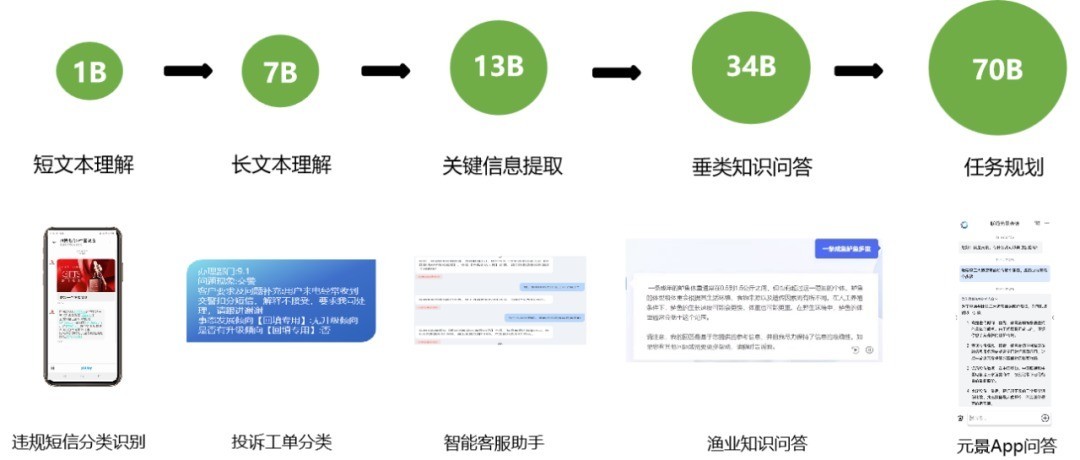
IT之家附论文联接:https://arxiv.org/abs/2406.10307h
评估基准:https://github.com/UnicomAI/UnicomBenchmark/tree/main/A-Eval干妹妹